




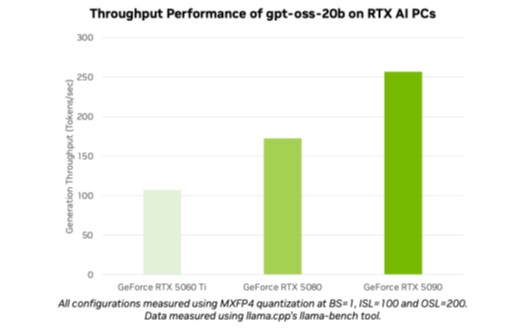
Модели нового поколения gpt-oss-20b и gpt-oss-120b открывают возможности для создания «агентских» AI-приложений. Миллионы пользователей, включая разработчиков и энтузиастов, теперь могут использовать эти модели на NVIDIA RTX AI ПК и рабочих станциях с помощью популярных инструментов и фреймворков — таких как Ollama, llama.cpp и Microsoft AI Foundry Local. Например, на ПК с видеокартой GeForce RTX 5090 достигается производительность до 256 токенов в секунду.
Новые модели обладают уникальными возможностями: они используют архитектуру mixture-of-experts. Обучение проходило на мощных GPU NVIDIA H100. Модели поддерживают контекст длиной до 131072 токенов — один из самых больших показателей для локального инференса, что особенно ценно для таких задач, как кодирование, анализ документов и сложные исследования.
Ollama — простой способ работать с моделями на системах с RTX
Для пользователей RTX AI ПК с 24 Гбайт видеопамяти компания рекомендует приложение Ollama. Оно поддерживает новые модели «из коробки» и полностью оптимизировано под архитектуру RTX, что позволяет быстро начать диалог с AI без дополнительных настроек.

Пользователи могут общаться с моделями, загружать PDF и текстовые файлы, работать с мультимодальными задачами и настраивать длину контекста для больших документов. Разработчики могут также использовать Ollama через командную строку или SDK для интеграции в свои приложения и рабочие процессы.
Дополнительные способы использования GPT-OSS на RTX
Для обладателей ПК с 16 Гбайт видеопамяти доступны варианты работы с моделями через llama.cpp, GGML, Microsoft AI Foundry Local и другие инструменты.
Особенно стоит отметить Microsoft AI Foundry Local — решение для локального инференса в среде Windows, которое можно запускать через командную строку, SDK или API. В скором времени ожидается поддержка NVIDIA TensorRT для RTX.





